统计摘要
摘要统计数据可以帮助人们快速理解数据集并做出明智的决策。许多有趣的数据集都存储在电子表格文件中。
¥Summary statistics help people quickly understand datasets and make informed decisions. Many interesting datasets are stored in spreadsheet files.
SheetJS 是一个用于从电子表格读取和写入数据的 JavaScript 库。
¥SheetJS is a JavaScript library for reading and writing data from spreadsheets.
该演示使用 SheetJS 处理电子表格中的数据。我们将探讨如何提取电子表格数据以及如何计算简单的汇总统计数据。该演示将重点关注两种通用数据表示形式:
¥This demo uses SheetJS to process data in spreadsheets. We'll explore how to extract spreadsheet data and how to compute simple summary statistics. This demo will focus on two general data representations:
-
"对象数组" 通过从 SheetJS 数据模型转换为更惯用的数据结构来简化处理。
¥"Arrays of Objects" simplifies processing by translating from the SheetJS data model to a more idiomatic data structure.
-
"密集的工作表" 直接分析 SheetJS 工作表。
¥"Dense Worksheets" directly analyzes SheetJS worksheets.
导入教程 是从工作簿中提取数据的指导示例。强烈建议先查看教程。
¥The Import Tutorial is a guided example of extracting data from a workbook. It is strongly recommended to review the tutorial first.
该浏览器演示在以下环境中进行了测试:
¥This browser demo was tested in the following environments:
| 浏览器 | 日期 |
|---|---|
| Chromium 133 | 2025-03-30 |
| Safari 18.3 | 2025-03-30 |
| Konqueror 22 | 2025-04-23 |
数据表示
�¥Data Representations
许多工作表都包含一个标题行,后跟许多数据行。每行是一个 "observation",每列是一个 "variable"。
¥Many worksheets include one header row followed by a number of data rows. Each row is an "observation" and each column is a "variable".
"对象数组" 解释使用更惯用的 JavaScript 模式。它适用于较小的数据集。
¥The "Array of Objects" explanations use more idiomatic JavaScript patterns. It is suitable for smaller datasets.
"密集的工作表" 方法性能更高,但代码模式让人想起 C。仅当传统模式速度慢得令人望而却步时,才鼓励使用底层方法。
¥The "Dense Worksheets" approach is more performant, but the code patterns are reminiscent of C. The low-level approach is only encouraged when the traditional patterns are prohibitively slow.
对象数组
¥Arrays of Objects
数据集的惯用 JavaScript 表示是一个对象数组。变量名称通常取自第一行。这些名称用作每个观察中的键。
¥The idiomatic JavaScript representation of the dataset is an array of objects. Variable names are typically taken from the first row. Those names are used as keys in each observation.
| Spreadsheet | JS Data |
|---|---|
| |
SheetJS sheet_to_json 方法 [^1] 可以从工作表对象生成对象数组。例如,以下代码片段获取一个测试文件并从第一个工作表创建一个数组数组:
¥The SheetJS sheet_to_json method[^1] can generate arrays of objects from a
worksheet object. For example, the following snippet fetches a test file and
creates an array of arrays from the first sheet:
const url = "https://xlsx.nodejs.cn/typedarray/iris.xlsx";
/* fetch file and pull file data into an ArrayBuffer */
const file = await (await fetch(url)).arrayBuffer();
/* parse workbook */
const workbook = XLSX.read(file, {dense: true});
/* first worksheet */
const first_sheet = workbook.Sheets[workbook.SheetNames[0]];
/* generate array of arrays */
const aoo = XLSX.utils.sheet_to_json(first_sheet);
密集的工作表
¥Dense Worksheets
SheetJS "dense" 工作表 [^2] 将单元格存储在数组的数组中。SheetJS read 方法 [^3] 接受特殊的 dense 选项来创建密集工作表。
¥SheetJS "dense" worksheets[^2] store cells in an array of arrays. The SheetJS
read method[^3] accepts a special dense option to create dense worksheets.
以下示例获取文件:
¥The following example fetches a file:
/* fetch file and pull file data into an ArrayBuffer */
const url = "https://xlsx.nodejs.cn/typedarray/iris.xlsx";
const file = await (await fetch(url)).arrayBuffer();
/* parse workbook */
const workbook = XLSX.read(file, {dense: true});
/* first worksheet */
const first_dense_sheet = workbook.Sheets[workbook.SheetNames[0]];
密集工作表的 "!data" 属性是单元格对象 [^4] 数组的数组。单元格对象包括数据类型和值等属性。
¥The "!data" property of a dense worksheet is an array of arrays of cell
objects[^4]. Cell objects include attributes including data type and value.
分析变量
¥Analyzing Variables
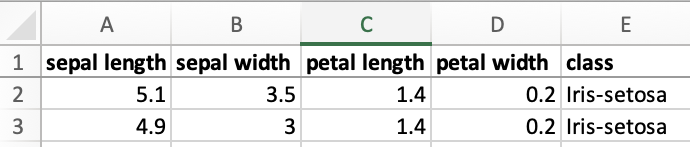
可以通过循环对象数组�并访问特定键来提取各个变量。例如,使用 Iris 数据集:
¥Individual variables can be extracted by looping through the array of objects and accessing specific keys. For example, using the Iris dataset:
- Array of Objects
- Dense Worksheet
以下代码片段显示了对象数组中的第一个条目:
¥The following snippet shows the first entry in the array of objects:
{
"sepal length": 5.1,
"sepal width": 3.5,
"petal length": 1.4,
"petal width": 0.2,
"class ": "Iris-setosa"
}
可以通过对每个对象建立索引来提取 sepal length 变量的值。以下代码片段打印萼片长度:
¥The values for the sepal length variable can be extracted by indexing each
object. The following snippet prints the sepal lengths:
for(let i = 0; i < aoo.length; ++i) {
const row = aoo[i];
const sepal_length = row["sepal length"];
console.log(sepal_length);
}
function SheetJSAoOExtractColumn() { const [col, setCol] = React.useState([]); React.useEffect(() => { (async() => { const ab = await (await fetch("/typedarray/iris.xlsx")).arrayBuffer(); const wb = XLSX.read(ab, {dense: true}); const aoo = XLSX.utils.sheet_to_json(wb.Sheets[wb.SheetNames[0]]); /* store first 5 sepal lengths in an array */ const col = []; for(let i = 0; i < aoo.length; ++i) { const row = aoo[i]; const sepal_length = row["sepal length"]; col.push(sepal_length); if(col.length >= 5) break; } setCol(col); })(); }, []); return ( <> <b>First 5 Sepal Length Values</b><br/> <table><tbody><tr>{col.map(sw => (<td>{sw}</td>))}</tr></tbody></table> </> ); }
sepal length 变量的列可以通过测试第一行中的单元格值来确定。
¥The column for the sepal length variable can be determined by testing the cell
values in the first row.
查找变量的列索引
¥Finding the column index for the variable
第一行单元格将是 "!data" 数组中的第一行:
¥The first row of cells will be the first row in the "!data" array:
const first_row = first_dense_sheet["!data"][0];
当循环第一行的单元格时,必须按以下顺序测试单元格:
¥When looping over the cells in the first row, the cell must be tested in the following order:
-
确认单元对象存在(条目不为空)
¥confirm the cell object exists (entry is not null)
-
单元格是文本单元格(
t属性将为"s"[^5])¥cell is a text cell (the
tproperty will be"s"[^5]) -
单元格值(
v属性 [^6])与"sepal length"匹配¥cell value (
vproperty[^6]) matches"sepal length"
let C = -1;
for(let i = 0; i < first_row.length; ++i) {
let cell = first_row[i];
/* confirm cell exists */
if(!cell) continue;
/* confirm cell is a text cell */
if(cell.t != "s") continue;
/* compare the text */
if(cell.v.localeCompare("sepal length") != 0) continue;
/* save column index */
C = i; break;
}
/* throw an error if the column cannot be found */
if(C == -1) throw new Error(`"sepal length" column cannot be found! `);
查找变量的值
¥Finding the values for the variable
找到列索引后,就可以扫描其余的行了。这次,单元格类型将为 "n"[^7](数字)。以下代码片段打印值:
¥After finding the column index, the rest of the rows can be scanned. This time,
the cell type will be "n"[^7] (numeric). The following snippet prints values:
const number_of_rows = first_dense_sheet["!data"].length;
for(let R = 1; R < number_of_rows; ++R) {
/* confirm row exists */
let row = first_dense_sheet["!data"][R];
if(!row) continue;
/* confirm cell exists */
let cell = row[C];
if(!cell) continue;
/* confirm cell is a numeric cell */
if(cell.t != "n") continue;
/* print raw value */
console.log(cell.v);
}
在线演示
¥Live Demo
以下代码片段打印萼片长度:
¥The following snippet prints the sepal lengths:
for(let i = 0; i < aoo.length; ++i) {
const row = aoo[i];
const sepal_length = row["sepal length"];
console.log(sepal_length);
}
function SheetJSDensExtractColumn() { const [msg, setMsg] = React.useState(""); const [col, setCol] = React.useState([]); React.useEffect(() => { (async() => { const ab = await (await fetch("/typedarray/iris.xlsx")).arrayBuffer(); const wb = XLSX.read(ab, {dense: true}); /* first worksheet */ const first_dense_sheet = wb.Sheets[wb.SheetNames[0]]; /* find column index */ const first_row = first_dense_sheet["!data"][0]; let C = -1; for(let i = 0; i < first_row.length; ++i) { let cell = first_row[i]; /* confirm cell exists */ if(!cell) continue; /* confirm cell is a text cell */ if(cell.t != "s") continue; /* compare the text */ if(cell.v.localeCompare("sepal length") != 0) continue; /* save column index */ C = i; break; } /* throw an error if the column cannot be found */ if(C == -1) return setMsg(`"sepal length" column cannot be found! `); /* store first 5 sepal lengths in an array */ const col = []; const number_of_rows = first_dense_sheet["!data"].length; for(let R = 1; R < number_of_rows; ++R) { /* confirm row exists */ let row = first_dense_sheet["!data"][R]; if(!row) continue; /* confirm cell exists */ let cell = row[C]; if(!cell) continue; /* confirm cell is a numeric cell */ if(cell.t != "n") continue; /* add raw value */ const sepal_length = cell.v; col.push(sepal_length); if(col.length >= 5) break; } setCol(col); setMsg("First 5 Sepal Length Values"); })(); }, []); return ( <><b>{msg}</b><br/><table><tbody> {col.map(sw => (<tr><td>{sw}</td></tr>))} </tbody></table></> ); }
平均值
¥Average (Mean)
对于给定的数字序列 ,平均值 定义为元素之和除以计数:
¥For a given sequence of numbers the mean is defined as the sum of the elements divided by the count:
用 JavaScript 术语来说,数组的平均值是数组中数字的总和除以数值总数。
¥In JavaScript terms, the mean of an array is the sum of the numbers in the array divided by the total number of numeric values.
非数字元素和数组孔不会影响总和,也不会对计数产生影响。算法应显式跟踪计数,并且不能假设数组 length 属性将是正确的计数。
¥Non-numeric elements and array holes do not affect the sum and do not contribute
to the count. Algorithms are expected to explicitly track the count and cannot
assume the array length property will be the correct count.
该定义与电子表格 AVERAGE 函数一致。
¥This definition aligns with the spreadsheet AVERAGE function.
AVERAGEA 与 AVERAGE 的不同之处在于对字符串和布尔值的处理:字符串值被视为零,布尔值映射到它们的强制数字等效项(true 是 1,false 是 0)。
¥AVERAGEA differs from AVERAGE in its treatment of string and Boolean values:
string values are treated as zeroes and Boolean values map to their coerced
numeric equivalent (true is 1 and false is 0).
一些 JavaScript 库实现了计算数组均值的函数。
¥Some JavaScript libraries implement functions for computing array means.
| 库 | 执行 |
|---|---|
jStat[^8] | 课本总和(最后除以) |
simple-statistics[^9] | Neumaier 补偿金额(最后除) |
stdlib.js[^10] | 试验平均值 (mean) / van Reeken (incrmean) |
文本薄总和
¥Textbook Sum
可以通过计算总和并除以计数来计算一系列值的平均值。
¥The mean of a sequence of values can be calculated by computing the sum and dividing by the count.
- Array of Objects
- Dense Worksheet
以下函数接受一个对象数组和一个键。
¥The following function accepts an array of objects and a key.
function aoa_average_of_key(aoo, key) {
let sum = 0, cnt = 0;
for(let R = 0; R < aoo.length; ++R) {
const row = aoo[R];
if(typeof row == "undefined") continue;
const field = row[key];
if(typeof field != "number") continue;
sum += field; ++cnt;
}
return cnt == 0 ? 0 : sum / cnt;
}
Live Demo (click to show)
function SheetJSAoOAverageKey() { const [avg, setAvg] = React.useState(NaN); function aoa_average_of_key(aoo, key) { let sum = 0, cnt = 0; for(let R = 0; R < aoo.length; ++R) { const row = aoo[R]; if(typeof row == "undefined") continue; const field = row[key]; if(typeof field != "number") continue; sum += field; ++cnt; } return cnt == 0 ? 0 : sum / cnt; } React.useEffect(() => { (async() => { const ab = await (await fetch("/typedarray/iris.xlsx")).arrayBuffer(); const wb = XLSX.read(ab, {dense: true}); const aoo = XLSX.utils.sheet_to_json(wb.Sheets[wb.SheetNames[0]]); setAvg(aoa_average_of_key(aoo, "sepal length")); })(); }, []); return ( <b>The average Sepal Length is {avg}</b> ); }
以下函数接受 SheetJS 工作表和列索引。
¥The following function accepts a SheetJS worksheet and a column index.
function ws_average_of_col(ws, C) {
const data = ws["!data"];
let sum = 0, cnt = 0;
for(let R = 1; R < data.length; ++R) {
const row = data[R];
if(typeof row == "undefined") continue;
const field = row[C];
if(!field || field.t != "n") continue;
sum += field.v; ++cnt;
}
return cnt == 0 ? 0 : sum / cnt;
}
Live Demo (click to show)
function SheetJSDenseAverageKey() { const [avg, setAvg] = React.useState(NaN); function ws_average_of_col(ws, C) { const data = ws["!data"]; let sum = 0, cnt = 0; for(let R = 1; R < data.length; ++R) { const row = data[R]; if(typeof row == "undefined") continue; const field = row[C]; if(!field || field.t != "n") continue; sum += field.v; ++cnt; } return cnt == 0 ? 0 : sum / cnt; } React.useEffect(() => { (async() => { const ab = await (await fetch("/typedarray/iris.xlsx")).arrayBuffer(); const wb = XLSX.read(ab, {dense: true}); const ws = wb.Sheets[wb.SheetNames[0]]; /* find column index */ const first_row = ws["!data"][0]; let C = -1; for(let i = 0; i < first_row.length; ++i) { let cell = first_row[i]; /* confirm cell exists */ if(!cell) continue; /* confirm cell is a text cell */ if(cell.t != "s") continue; /* compare the text */ if(cell.v.localeCompare("sepal length") != 0) continue; /* save column index */ C = i; break; } setAvg(ws_average_of_col(ws, C)); })(); }, []); return ( <b>The average Sepal Length is {avg}</b> ); }
当对许多相似大小的值求和时,教科书方法会遇到数值问题。随着元素数量的增加,总和的绝对值会比各个值的绝对值大几个数量级,并且有效数字会丢失。
¥The textbook method suffers from numerical issues when many values of similar magnitude are summed. As the number of elements grows, the absolute value of the sum grows to orders of magnitude larger than the absolute values of the individual values and significant figures are lost.
van Reeken
教科书方法中的一些问题可以通过微分技术来解决。可以计算并更新平均值的估计,而不是计算总和。
¥Some of the issues in the textbook approach can be addressed with a differential technique. Instead of computing the whole sum, it is possible to calculate and update an estimate for the mean.
van Reeken 数组均值可以用一行 JavaScript 代码实现:
¥The van Reeken array mean can be implemented in one line of JavaScript code:
for(var n = 1, mean = 0; n <= x.length; ++n) mean += (x[n-1] - mean)/n;
Math details (click to hide)
令 为前 个元素的平均值(其中 )。前 个元素的平均值遵循一个简单的关系:
¥Let be the mean of the first elements (where ). The mean of the first elements follows a simple relation:
第一个元素的��平均值是 。通过定义 ,递归关系也适用于 :
¥The mean of the first element is . By defining , the recurrence relation also holds for :
将作为递归的初始条件。
¥ will serve as the initial condition for the recurrence.
JavaScript 从零开始索引: 代表 x[0],通常 代表 x[m-1]。
¥JavaScript is zero-indexed: is x[0] and generally is x[m-1].
调整从零开始的索引后,以下代码计算递归:
¥Adjusting for zero-based indexing, the following code calculates the recurrence:
/* data array */
var x = [ /* ... data ... */ ];
/* initial condition M[x;0] = 0 */
var mean = 0;
/* loop through each value in the array */
for(var m = 0; m < x.length; ++m) {
/* store the old mean M[x;m] */
var mean_m = mean;
/* get the next data point x_{m+1} */
var x_m1 = x[m];
/* calculate the new mean M[x;m+1] */
var mean_m1 = mean_m + (x_m1 - mean_m) / (m + 1);
/* update the mean */
mean = mean_m1;
}
可以通过直接赋值给 mean 来简洁地实现:
¥This can be succinctly implemented by assigning to mean directly:
for(var m = 0, mean = 0; m < x.length; ++m) {
mean = mean + (x[m] - mean) / (m + 1);
}
可以使用加法赋值运算符 (+=) 进一步简化:
¥This can be condensed further by using the addition assignment (+=) operator:
for(var m = 0, mean = 0; m < x.length; ++m) mean += (x[m] - mean) / (m + 1);
替换 n = m+1 得到最终代码表达式:
¥Replacing n = m+1 yields the final code expression:
for(var n = 1, mean = 0; n <= x.length; ++n) mean += (x[n-1] - mean) / n;
- Array of Objects
- Dense Worksheet
以下函数接受一个对象数组和一个键。
¥The following function accepts an array of objects and a key.
function aoa_mean_of_key(aoo, key) {
let mean = 0, cnt = 0;
for(let R = 0; R < aoo.length; ++R) {
const row = aoo[R];
if(typeof row == "undefined") continue;
const field = row[key];
if(typeof field != "number") continue;
mean += (field - mean) / ++cnt;
}
return cnt == 0 ? 0 : mean;
}
Live Demo (click to show)
function SheetJSAoOMeanKey() { const [avg, setAvg] = React.useState(NaN); function aoa_mean_of_key(aoo, key) { let mean = 0, cnt = 0; for(let R = 0; R < aoo.length; ++R) { const row = aoo[R]; if(typeof row == "undefined") continue; const field = row[key]; if(typeof field != "number") continue; mean += (field - mean) / ++cnt; } return cnt == 0 ? 0 : mean; } React.useEffect(() => { (async() => { const ab = await (await fetch("/typedarray/iris.xlsx")).arrayBuffer(); const wb = XLSX.read(ab, {dense: true}); const aoo = XLSX.utils.sheet_to_json(wb.Sheets[wb.SheetNames[0]]); setAvg(aoa_mean_of_key(aoo, "sepal length")); })(); }, []); return ( <b>The average Sepal Length is {avg}</b> ); }
以下函数接受 SheetJS 工作表和列索引。
¥The following function accepts a SheetJS worksheet and a column index.
function ws_mean_of_col(ws, C) {
const data = ws["!data"];
let mean = 0, cnt = 0;
for(let R = 1; R < data.length; ++R) {
const row = data[R];
if(typeof row == "undefined") continue;
const field = row[C];
if(!field || field.t != "n") continue;
mean += (field.v - mean) / ++cnt;
}
return cnt == 0 ? 0 : mean;
}
Live Demo (click to show)
function SheetJSDenseMeanKey() { const [avg, setAvg] = React.useState(NaN); function ws_mean_of_col(ws, C) { const data = ws["!data"]; let mean = 0, cnt = 0; for(let R = 1; R < data.length; ++R) { const row = data[R]; if(typeof row == "undefined") continue; const field = row[C]; if(!field || field.t != "n") continue; mean += (field.v - mean) / ++cnt; } return cnt == 0 ? 0 : mean; } React.useEffect(() => { (async() => { const ab = await (await fetch("/typedarray/iris.xlsx")).arrayBuffer(); const wb = XLSX.read(ab, {dense: true}); const ws = wb.Sheets[wb.SheetNames[0]]; /* find column index */ const first_row = ws["!data"][0]; let C = -1; for(let i = 0; i < first_row.length; ++i) { let cell = first_row[i]; /* confirm cell exists */ if(!cell) continue; /* confirm cell is a text cell */ if(cell.t != "s") continue; /* compare the text */ if(cell.v.localeCompare("sepal length") != 0) continue; /* save column index */ C = i; break; } setAvg(ws_mean_of_col(ws, C)); })(); }, []); return ( <b>The average Sepal Length is {avg}</b> ); }
该算法一般归因于 Welford[^11]。然而,原论文并没有提出这种计算均值的算法!
¥This algorithm is generally attributed to Welford[^11]. However, the original paper does not propose this algorithm for calculating the mean!
包括 Neely[^12] 在内的程序员将一种不同的算法归因于 Welford。van Reeken[^13] 报告了本节中介绍的算法的成功。
¥Programmers including Neely[^12] attributed a different algorithm to Welford. van Reeken[^13] reported success with the algorithm presented in this section.
Knuth[^14] 错误地将平均值的实现归因于 Welford。
¥Knuth[^14] erroneously attributed this implementation of the mean to Welford.
"半数值算法"(TAOCP 第 2 卷)中的错误已解决![^15]
¥The error in "Seminumerical Algorithms" (TAOCP Volume 2) was addressed![^15]
SheetJS 队友已收到 Knuth 奖励支票以表彰其贡献。
¥A SheetJS teammate has received a Knuth Reward Check for the contribution.
[^1]: 见 sheet_to_json 于 "实用工具"
¥See sheet_to_json in "Utilities"
[^2]: 见 "密集模式" 于 "实用工具"
¥See "Dense Mode" in "Utilities"
[^3]: 见 read 于 "读取文件"
[^4]: 见 "密集模式" 于 "实用工具"
¥See "Dense Mode" in "Utilities"
[^5]: 见 "单元格类型" 于 "单元格对象"
¥See "Cell Types" in "Cell Objects"
[^6]: 见 "基本值" 于 "单元格对象"
¥See "Underlying Values" in "Cell Objects"
[^7]: 见 "单元格类型" 于 "单元格对象"
¥See "Cell Types" in "Cell Objects"
[^8]: 请参阅 jStat 文档中的 mean()。
¥See mean() in the jStat documentation.
[^9]: 请参阅 simple-statistics 文档中的 mean。
¥See mean in the simple-statistics documentation.
[^10]: 请参阅 stdlib.js 文档中的 incrsum。
¥See incrsum in the stdlib.js documentation.
[^11]: 请参阅《Technometrics》第 4 卷第 3 卷(1962 年 8 月)中的 "关于计算校正平方和和乘积的方法的注释"。
¥See "Note on a Method for Calculated Corrected Sums of Squares and Products" in Technometrics Vol 4 No 3 (1962 August).
[^12]: 参见 CACM 第 9 卷第 7 期中的 "几种计算均值、标准差和相关系数的算法比较"(1966 年 7 月)。
¥See "Comparison of Several Algorithms for Computation of Means, Standard Deviations and Correlation Coefficients" in CACM Vol 9 No 7 (1966 July).
[^13]: 参见 CACM 第 11 卷第 3 期(1968 年 3 月)中的 "处理尼利算法"。
¥See "Dealing with Neely's Algorithms" in CACM Vol 11 No 3 (1968 March).
[^14]: 请参阅“计算机编程的艺术:半数值算法”第三版第 232 页。
¥See "The Art of Computer Programming: Seminumerical Algorithms" Third Edition page 232.
[^15]: 查看 TAOCP 站点中的 "第 2 卷勘误表(2021 年之后)"
¥See the "Errata for Volume 2 (after 2021)" in the TAOCP site